

|
Today we are asserting a new Amazon Comprehend characteristic for intelligent document processing (IDP). This function will allow you to classify and extract entities from PDF files, Microsoft Word information, and illustrations or photos instantly from Amazon Comprehend with no you needing to extract the text initial.
Lots of shoppers have to have to process paperwork that have a semi-structured format, like illustrations or photos of receipts that were scanned or tax statements in PDF structure. Right until these days, these buyers first wanted to preprocess those people files to flatten them into machine-readable textual content, which can minimize the good quality of the doc context. Then they could use Amazon Understand to classify and extract entities from people preprocessed files.
Now with Amazon Comprehend for IDP, consumers can process their semi-structured documents, these as PDFs, docx, PNG, JPG, or TIFF pictures, as effectively as basic-textual content documents, with a solitary API simply call. This new element combines OCR and Amazon Comprehend’s existing natural language processing (NLP) capabilities to classify and extract entities from the files. The customized doc classification API makes it possible for you to organize paperwork into groups or lessons, and the customized-named entity recognition API allows you to extract entities from paperwork like product or service codes or small business-certain entities. For illustration, an insurance coverage corporation can now procedure scanned customers’ promises with less API calls. Utilizing the Amazon Understand entity recognition API, they can extract the shopper quantity from the promises and use the customized classifier API to sort the declare into the various insurance coverage categories—home, auto, or particular.
Starting right now, Amazon Comprehend for IDP APIs are out there for genuine-time inferencing of information, as effectively as for asynchronous batch processing on significant document sets. This characteristic simplifies the doc processing pipeline and decreases advancement exertion.
Obtaining Commenced
You can use Amazon Understand for IDP from the AWS Administration Console, AWS SDKs, or AWS Command Line Interface (CLI).
In this demo, you will see how to asynchronously method a semi-structured file with a tailor made classifier. For extracting entities, the measures are distinct, and you can discover how to do it by checking the documentation.
In buy to process a file with a classifier, you will initial need to train a customized classifier. You can observe the ways in the Amazon Understand Developer Tutorial. You require to practice this classifier with simple textual content facts.
Immediately after you coach your custom classifier, you can classify files applying possibly asynchronous or synchronous operations. For applying the synchronous procedure to review a solitary doc, you want to produce an endpoint to run actual-time evaluation making use of a custom model. You can obtain a lot more facts about authentic-time examination in the documentation. For this demo, you are likely to use the asynchronous procedure, positioning the documents to classify in an Amazon Straightforward Storage Company (Amazon S3) bucket and working an investigation batch task.
To get commenced classifying files in batch from the console, on the Amazon Comprehend web page, go to Analysis jobs and then Make occupation.

Then you can configure the new examination task. First, enter a name and decide Custom made classification and the customized classifier you designed earlier.
Then you can configure the enter details. Initially, find the S3 site for that data. In that site, you can put your PDFs, pictures, and Phrase Documents. Because you are processing semi-structured paperwork, you require to pick One particular document for every file. If you want to override Amazon Understand settings for extracting and parsing the document, you can configure the Advanced doc input options.
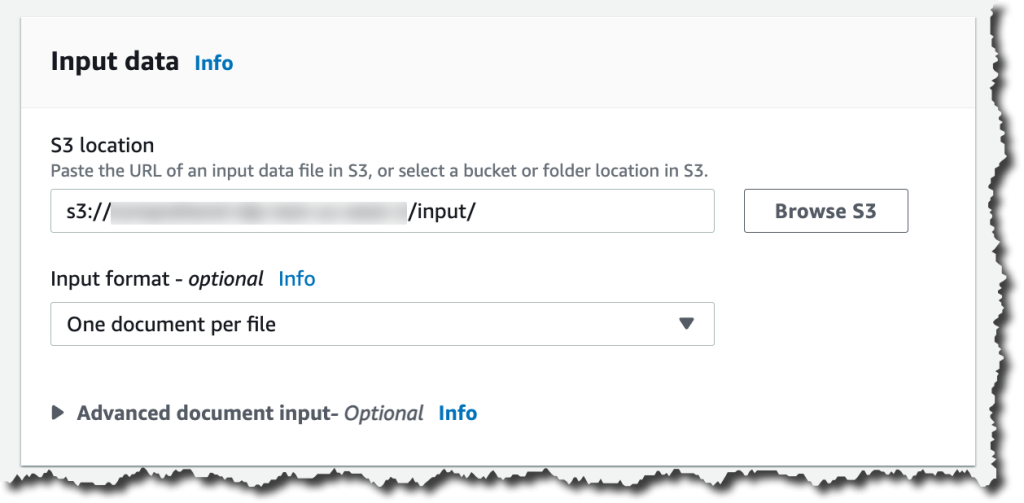
Just after configuring the input info, you can decide on where by the output of this analysis should really be saved. Also, you want to give obtain permissions for this examination career to examine and produce on the specified Amazon S3 areas, and then you are completely ready to develop the task.

The occupation can take a several minutes to run, depending on the measurement of the input. When the work is all set, you can verify the output results. You can discover the benefits in the Amazon S3 spot you specified when you established the job.
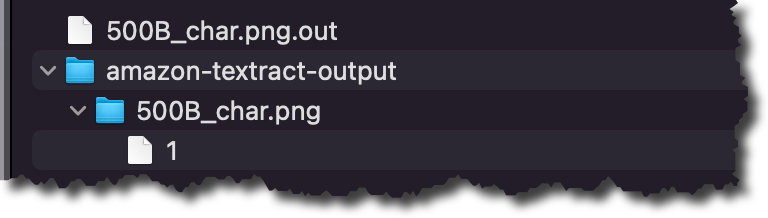
In the outcomes folder, you will come across a .out file for each of the semi-structured data files Amazon Understand categorised. The .out file is a JSON, in which just about every line represents a site of the document. In the amazon-textract-output directory, you will find a folder for each categorised file, and inside of that folder, there is a person file for each website page from the primary file. Those people site documents contain the classification results. To study more about the outputs of the classifications, look at the documentation webpage.
Accessible Now
You can get begun classifying and extracting entities from semi-structured data files like PDFs, photos, and Phrase Files asynchronously and synchronously today from Amazon Understand in all the Areas in which Amazon Understand is available. Understand additional about this new start in the Amazon Comprehend Developer Guideline.
— Marcia